Shin Asakawa's GitHub.io
2025年02月28日 九州大学,理化学研究所
(4) 依頼の趣旨:
MPNet のような文埋め込みモデルは単語モデルと異なり,文脈による曖昧性,たとえばアップルが果物を指すのかコンピューターを指すのかが解決できる点に特徴がある. 文脈処理は柔軟な知能の特性であるが,より注目すべき点は,一般に言語モデルは同じアルゴリズムを言語ではない情報に適用して問題を解決できるということである. 再帰(あるいは入れ子,recursion)は人間の高度な認知の基礎とされ(Corballis, 2011), そこでは言語そのものではなく言語処理を可能にした計算としての再帰が人類の進化上の特徴であり,多次元空間における階層的な情報を扱うことができるようになったので,複数の階層にまたがる部分全体関係の把握による概念や社会組織・制度の構造化や,部品(パーツ)を組み合わせた高度な道具・装置としてのハードウェア・ソフトウェアの製作が可能になったとされる. 実際にヒトの脳でも,音声言語・書字言語とも,たとえば下前頭回(文法と抑揚)や腹側後頭側頭葉の紡錘状回(顔と文字・単語)のように,機能が局在する左半球の領野と相同の右半球の領野に類同性をもった情報の処理が局在する. 言語モデルの重要な構成要素はトランスフォーマーであるが,左半球において言語理解の「中枢」とされる側頭頭頂結合部の右半球の相同領野の機能は注意制御とされる. 開放系情報科学チームでは,今後柔軟な知能として量子アルゴリズムによる知覚認知の曖昧性解決を研究するが,言語モデル研究において理論的側面と実際の応用がどのようにつながっているかを理解することは,上で指摘した対応関係がたんなる現象にとどまらず数理的な基礎を持つかどうかを吟味する上で不可欠である. 浅川先生は言語モデルの理論的側面と実践的側面の対応関係のエキスパートであるので,ご講演をお願いしたい.
Negative sampling (Mikolov+2013)
An alternative to the hierarchical softmax is Noise Contrastive Estimation (NCE), which was introduced by Gutmann&Hyvarinen [4] and applied to language modeling by Mnih&Teh[11]. NCE posits that a good model should be able to differentiate data from noise by means of logistic regression. This is similar to hinge loss used by Collobert&Weston [2] who trained the models by ranking the data above noise. While NCE can be shown to approximately maximize the log probability of the softmax, the Skip-gram model is only concerned with learning high-quality vector representations, so we are free to simplify NCE as long as the vector representations retain their quality. We define Negative sampling (NEG) by the objective \(\log\sigma\left(\nu_{w_{O}}^{\prime\top},\nu_{w_{I}}\right)+\sum_{i=1}^{k}\mathbb{E}_{w_{i}\sim P_{n}(w)}\left[\log\sigma\left(-\nu_{w_{i}}^{\prime\top}\nu_{w_{I}}\right)\right] \tag{negative sampling}\) which is used to replace every log $P(wO|wI)$ term in the Skip-gram objective. Thus the task is to distinguish the target word $w_O$ from draws from the noise distribution $P_n(w)$ using logistic regression, where there are $k$ negative samples for each data sample. Our experiments indicate that values of k in the range 5–20 are useful for small training datasets, while for large datasets the k can be as small as 2–5. The main difference between the Negative sampling and NCE is that NCE needs both samples and the numerical probabilities of the noise distribution, while Negative sampling uses only samples. And while NCE approximately maximizes the log probability of the softmax, this property is not important for our application.
Both NCE and NEG have the noise distribution Pn(w)as a free parameter. We investigated a number of choices for Pn(w) and found that the unigram distribution $U(w)$ raised to the 3/4rd power (i.e., U(w)^{3/4}/Z$) outperformed significantly the unigram and the uniform distributions, for both NCE and NEG on every task we tried including language modeling (not reported here).
A4. Word2vec を用いた単語の意味空間
- ピラミッド・パームツリー・テスト: 認知症検査 (意味連合検査,佐藤(2022))
- ターゲットと最も関連のあると考えられる選択肢を一つ選べ。
- ターゲット: オートバイ,選択肢: 麦わら帽子,帽子,ヘルメット,兜
- ターゲット: かもめ,選択肢: 水田,池,滝,海
- ターゲット: 柿,選択肢: 五重塔,教会,病院,駅


A.4 Word2vec を用いた単語の意味空間(2)

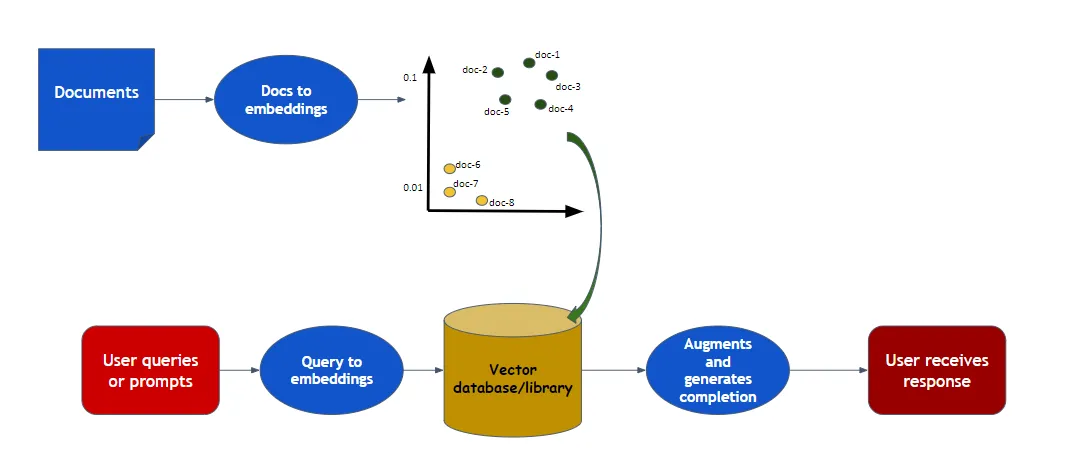
A.5 RAG (Retrieval Augmented Generation)
文献
- Mikolov+2013, word2vec オリジナル論文
- [浅川+2018, Analogy comprehension between psychological experiments and word embedding models, Asakawa+2018] (https://komazawa-deep-learning.github.io/2018jsai.pdf)
- 近藤・浅川 (2017) 日本語 Wikipedia の word2vec 表現と語彙特性の関係
World model
 Rao(1999)
Rao(1999)


GPT-4
chatGPT の後続モデルである GPT-4 では,マルチモーダル,すなわち,視覚と言語の統合が進んだ。
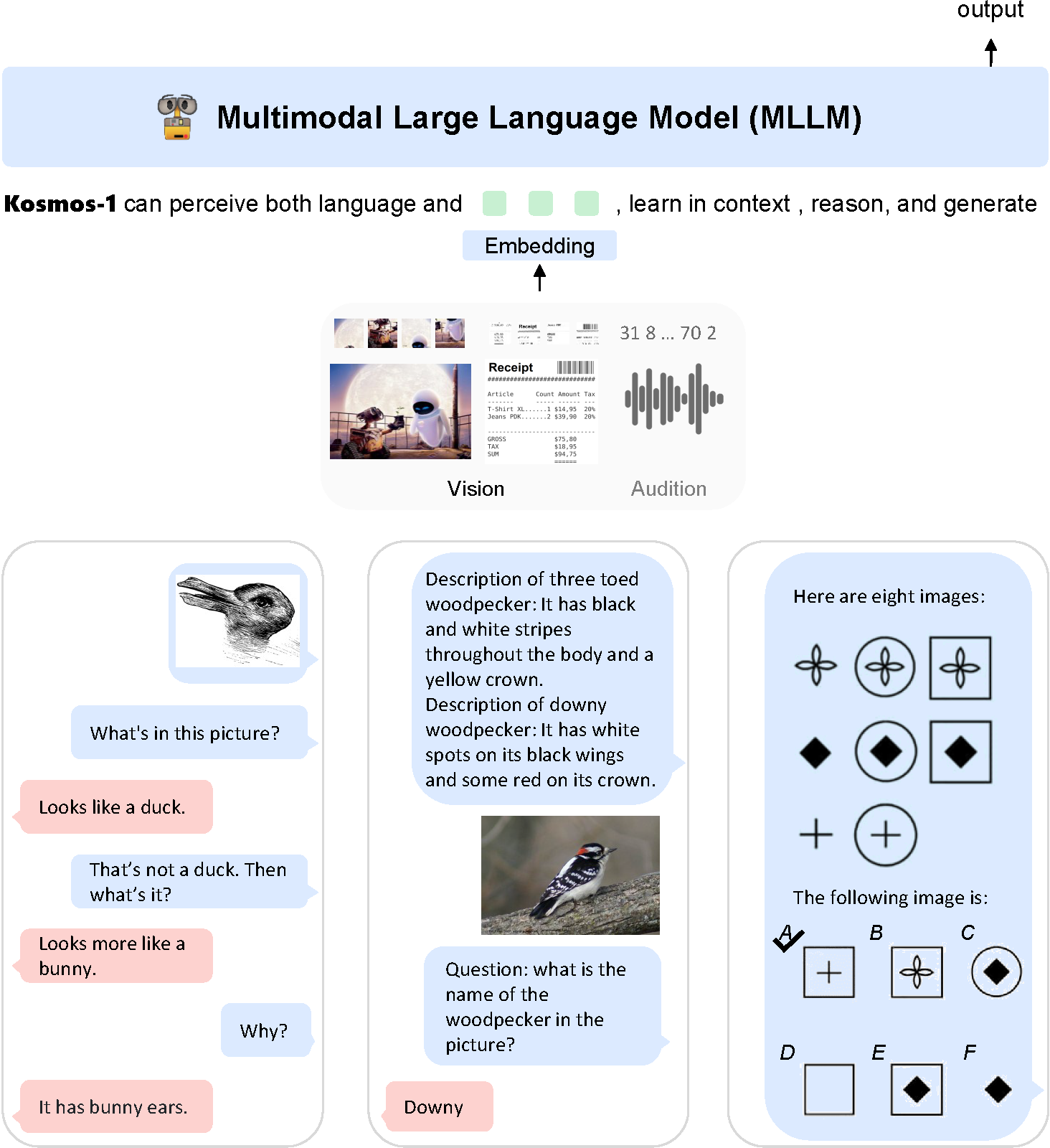
まず第一に,大規模ではない,言語モデルについて考えます。 言語モデルは,機械翻訳などでも使われる技術です。 ですから,DeepL や Google 翻訳で,使っている方もいることでしょう。
chatGPT を使える方は,上記太字のキーワードについて,chatGPT に質問してみることをお勧めします。 とりわけ 注意 については,認知,視覚,心理学との関連も深く,注意の障害は,臨床,教育,発達などの分野と関係する でしょう。



上図で,matmul は行列の積,scale は,平均 0 分散 1 への標準化,mask は 0 と 1 とで,データを制限すること
,
softmax はソフトマックス関数である。
トランスフォーマーの注意とは,このソフトマックス関数である。

リカレントニューラルネットワークの時間展開

From [@2014Sutskever_Sequence_to_Sequence]
- Bow: Bag of Words 単語の袋。ある文章を表現する場合に,各単語の表現を集めて袋詰めしたとの意味。 従って語順が考慮されない。 「犬が男を噛んだ」 と「男が犬を噛んだ」では同じ表現となる。 LSA, LDA, fastText なども同じような表現を与える。
- TF-IDF: 単語頻度 (Term Frequency) と 逆(Inverse) 文書頻度 (Document Frequency) で文書のベクトル表現を定義する手法。 何度も出現する単語は重要なので単語頻度が高い文書には意味がある。 一方,全ての文書に出現する単語は重要とは言えないので単語の出現る文書の個数の逆数の対数変換を用いる。 このようにしてできた文章表現を TF-IDF と呼ぶ。
- ワンホット表現: ベクトルの要素のうち一つだけが “1” であり他は全て “0” である疎なベクトルのこと。 一つだけが “熱い” あるいは “辛い” ベクトルという呼び方であるが,以前は one-of-$k$ 表現 (MacKay の PRML など) と呼ばれていた。 最近では,ワンホット表現,あるいは ワンホットベクトル (おそらく命名者は Begnio 一派) と呼ばれることが多い。 ワンホットベクトルを学習させると時間がかかるという計算上の弱点が生じる。 典型的な誤差逆伝播法による学習では,下位層の入力値に結合係数を掛けた値で結合係数を更新する。 従って,下位層の値のほとんどが “0” であるワンホットベクトルは学習効率が落ちることになる。 そこで Elman はワンホットベクトルを実数値を持つ多次元ベクトルに変換してから用いることを行った。 上の Elman ネットによる文法学習において,ニューロン数 10 の単語埋め込み層と書かれた層がこれに該当する。 単語埋め込み層を用いることで学習効率が改善し,word2vec などの 分散ベクトルモデル へと発展する。
- 埋め込み表現: すべての要素が実数であるベクトルで表されるニューラルネットワークのある層の状態。
言語モデル Language model
- 文献では言語モデルを LM と表記される。
- 統計的言語モデル statistical language model。言語系列に確率
を与えるモデルの総称。良い言語モデル LM は,有意味文に高い確率を与え,曖昧な文には低い確率を与える。言語モデル
は人工知能の問題。
- n-gram 言語モデル
- 指標: BELU, perplexity
- 課題: NER, POS, COL, Summary, QA, Translation
N-グラム言語モデル
- 類似した言語履歴 $h$ について, n-gram 言語モデルは言語履歴 $h$ によって言語が定まることを言います。
- 実用的には n-gram 言語モデルは $n$ 語の単語系列パターンを表象するモデルです。
- n-gram 言語モデルでは $n$ の次数増大に従って,パラメータは指数関数的に増大します。
- すなわち高次 n グラム言語モデルのパラメータ推定に必要な言語情報のコーパスサイズは,次数増大に伴って,急激不 足します
- Wikipedia からの引用では次式: \(p(w_1,\dots,w_m)=\prod_{i=1}^{m} P(w_i\vert w_1,\ldots,w_{i-1})\simeq \prod_{i=1}^{m}p(w_i\vert w_{i-(n-1)},\l dots,w_{i-1})\)
- 上式では $m$ ですが,伝統的に $n$ グラムと呼びます。$n=1$ であれば直前の 1 つを考慮して 次語を予測することになります。
余談: グラム (gram)
- $n=0$: ヌルグラム null-gram
- $n=1$: ユニグラム uni-gram
- $n=2$: バイグラム bi-gram
- $n=3$: トリグラム tri-gram
などと呼ばれる。
Manning1999(p.193) によると単語 gram はギリシャ語由来の単語である。 従って gram に付ける数接頭辞もギリシャ語である教養を持つべきである。 そうだとすると $n=1$: mono-gram, $n=2$: di-gram, $n=4$: tetra-gram が教養です。 $n=3$ はギリシャ,ローマ共通で tri-gram となる。 日常会話では $n=4$ をクワッドグラム(ラテン語由来)やフォーグラムと呼ぶことも多い。
再帰型 (リカレント) ニューラルネットワークモデル
リカレントニューラルネットワークモデル (Recurrent Neural Networks, 以下 RNN) は 系列情報処理 (serial i nformation processings) を扱うニューラルネットワークモデルである。 観察された証拠から次に生じる事象を予想することは,生物の生存にとって意味ある情報処理であると考える。 その適用範囲を思いつくままに考えてみると以下のような事柄が含まれる。
- 生物の生存戦略
- 制御,予測。天気予報,ロケットなどの弾道制御
- データ処理
- 未来予想,SF 的,心理学的,哲学的,歴史的意味あいも含めて。身近な例では占いや経済予測も含まれます
一方,機械学習,ディープラーニングの分野では,系列情報処理の中の 言語モデル (Language models) として頻用さ れている。 昨今の 自然言語処理 (Natural Language Processings, 以下 NLP) では 機械翻訳 や種々の処理に採用されてき た。 2014 年以降の話題として 注意 (attention) を言語モデルに取り込んで精度向上を目指す動向が活発である。 注意 と 言語 とはどちらも 心理学分野 で注目すべき話題であろう。 RNN の応用可能性は神経心理学にとって一考の価値があるモデルと言えるだろう。
2018 年,複数の言語課題で人間の成績を凌駕する自然言語処理モデルが提案された。 このことから自然言語処理モデルを神経心理学に応用する機運は熟していると考えられる。
リカレントニューラルネットワークの成果
- 手書き文字認識 Graves2009
- 音声認識 Graves2013, Grave&Jaitly(2014)
- 手書き文字生成 Graves2013
- 系列学習 Sutskever2014
- 機械翻訳 Bahdanau+(2014)
- 機械翻訳 Luong+(2015)
- 画像脚注付け Vinyals+(2014)
- 注意つき画像脚注生成
- 構文解析 Vinayals+(2014)
- プログラムコード生成 Zaremba2015
- 対話生成 Vinyals2014
- ニューラルチューリングマシン NTM Graves et. al, (2014)
- 世界モデル Ha&Schmithuber(2018). 我々を取り巻く世界のイ メージは脳内のメンタルモデルである。誰しも全ての世界,政府,国を想像できない。 我々は現実世界の表象するコンセプトを選んでその関係を使うだけだ,と フォレスター は言ったらしい。
参考文献
- リカレントニューラルネットワーク
- 浅川伸一 (2003) 単純再帰型ニューラルネットワークの心理学モデルとしての応用可能性, 心理学評論, 46(2), 274-287.
- 浅川伸一 (2016) リカレントニューラルネットワーク, 日本人工知能学会編,人工知能学事典新版,共立出版
- 浅川伸一 (2016) リカレントニューラルネットワークによる文法学習, 日本人工知能学会編,人工知能学事典新版,共立出版
2. 再帰型ニューラルネットワーク
前史 NETtalk
系列情報処理を扱った初期のニューラルネットワーク例として NETTalk が挙げられる。 NETTalk は文字を音読するネットワークであり,下図のような構成になっている。 アルファベット 7 文字を入力して,空白はアンダーラインで表現されている。 中央の文字の発音を学習する 3 層のニューラルネットワークである。 NETTalk は 7 文字幅の窓を移動させながら逐次中央の文字の発音を学習した。 たとえば /I ate the apple/ という文章では “the” を “ザ” ではなく “ジ” と発音することにできる。
印刷単語の読字過程のニューラルネットワークモデルである SM89, PMSP96 で用いられた発音表現は ARPABET の亜種である。
Python では nltk ライブラリを使うと ARPABET の発音を得ることができる (ARPABET のデモ![]()
- NETTalk: Sejnowski, T.J. and Rosenberg, C. R. (1987) Parallel Networks that Learn to Pronounce English Text, Complex Systems 1, 145-168.
- SM89: Seidenberg, M. S. & McClelland, J. L. (1989). A distributed, developmetal model of word recognition and naming. Psychological Review, 96(4), 523–568.
- PMSP96: Plaut, D. C., McClelland, J. L., Seidenberg, M. S. & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103, 56–115.

Sejnowski (1986) Fig. 2
単純再帰型ニューラルネットワーク (SRN)
NETTalk を先がけとして 単純再帰型ニューラルネットワーク Simple Recurrent Neural networks (SRN) が提案された。 発案者の名前で Jordan ネット,Elman ネット と呼ばれる。
- JordanNet: Joradn, M.I. (1986) Serial Order: A Parallel Distributed Processing Approach, UCSD tech report.
- ElmanNet: Elman, J. L. (1990)Finding structure in time, Cognitive Science, 14, 179-211.
Jordan ネットも Elman ネットも上位層からの 帰還信号 を持つ。 これを フィードバック結合 と呼び,位置時刻前の状態が次の時刻に使われます。 Jordan ネットでは一時刻前の出力層の情報が用いられます(下図)。

図:マイケル・ジョーダン発案ジョーダンネット [@1986Jordan]
多くの機械学習アルゴリズムを提案し続けている影響力のある 人です。 長らく機械学習の国際雑誌の編集長でした。 2018年 AI 革命は未だ起こっていない と言い出して議論を呼びました。
一方,Elman ネットでは一時刻前の中間層の状態がフィードバック信号として用いられます。

図:ジェフ・エルマン発案のエルマンネット[@lman1990],[@Elman1993]
どちらも一時刻前の状態を短期記憶として保持して利用するのだが,実際の学習では一時刻前の状態をコピーして保存して おくだけで,実際の学習では通常の 誤差逆伝播法 すなわちバックプロパゲーション法が用いられる。 上 2 つの図に示したとおり U と W とは共に中間層への結合係数であり,V は中間層から出力層への結合係数である。 Z=I と書き点線で描かれている矢印はコピーするだけですので学習は起こらない。 このように考えれば SRN は 3 層のニューラルネットワークであることが分かる。
SRN はこのような単純な構造にも関わらず チューリング完全 であろうと言われてきた。 すなわちコンピュータで計算可能な問題はすべて計算できるくらい強力な計算機だという意味である。
- Jordan ネットは出力層の情報を用いるため 運動制御 に
- Elan ネットは内部状態を利用するため 言語処理 に
それぞれ用いられる。 従って 失行 aparxia (no matter what kind of apraxia such as ‘ideomotor’ or ‘conceptual’),行為障害 のモデルを考える場合 Jordan ネットは考慮すべき選択肢の候補の一つとなるだろう。
多様な RNN とその万能性
双方向 RNN や LSTM を紹介する前に,カルパシーのブログ1 から下図に引用します。 下の 2 つ図ではピンク色が入力層,緑が中間層,青が出力層を示しています。
図は彼のブログから引用です。
蛇足ですがブログのタイトルが unreasonable effectiveness of RNN です。
過去の偉大な論文 Wiegner (1960), Hamming (1967), Halevy (2009) からの パクリ 敬意を表したオマージュです。
“unreasonable effectiveness of [science|mathematics|data]” $\ldots$ www
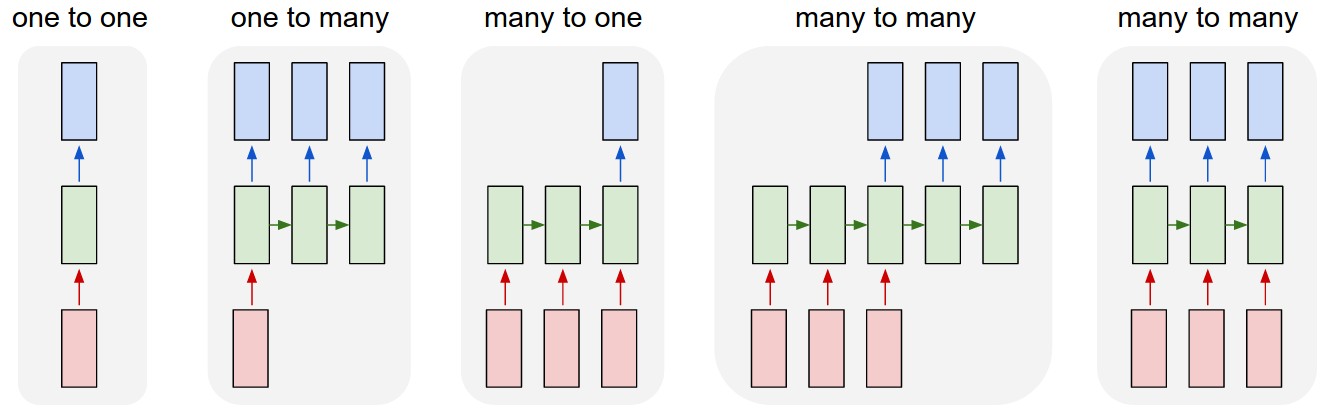
RNN variations from <http://karpathy.github.io/2015/05/21/rnn-effectiveness/>
- 上図最左は通常の多層ニューラルネットワークで画像認識,分類,識別問題に用いられます。
- 上図左から 2 つ目は,画像からの文章生成
- 上図中央,左から 3 つ目は,極性分析,文章のレビュー,星の数推定
- 上図右から 2 つ目は翻訳や文章生成
- 上図最右はビデオ分析,ビデオ脚注付け
などに用いられます。これまで理解を促進する目的で中間層をただ一層として描いてきました。 ですがが中間層は多層化されていることの方が多いこと,中間層各層のニューロン数は 1024 程度まで用いられていることには注意してください。
数は各層のニューロン数が 4 つである場合の数値例を示しています。 入力層では ワンホット 表現
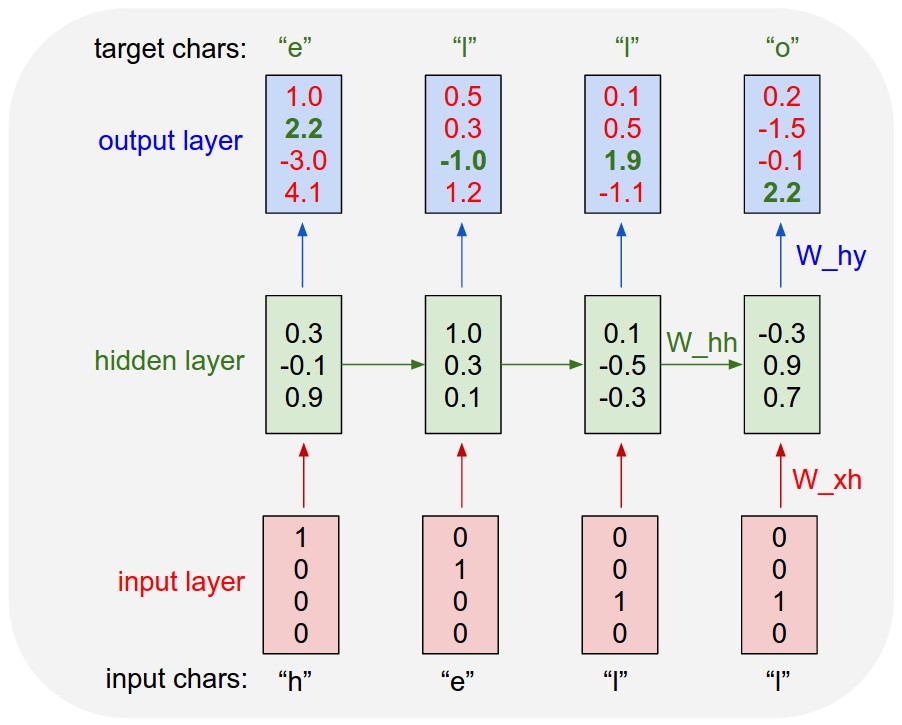
RNN variations from <http://karpathy.github.io/2015/05/21/rnn-effectiveness/>
[@1991Siegelmann_RNN_universal] said Turing completeness of RNN.
2.3. リカレントニューラルネットワークの時間展開
一時刻前の状態を保持して利用する SRN は下図左のように描くことができます。同時に時間発展を考慮すれば下図右のように描くことも可能です。
Time unfoldings of recurrent neural networks
上図右を頭部を 90 度右に傾けて眺めてください。あるいは同義ですが上図右を反時計回りに 90 度回転させたメンタルローテーションを想像してください。 このことから “SRN とは時間方向に展開したディープラーニングである” ことが分かります。
2.4. エルマンネットによる言語モデル
下図に エルマン が用いたネットワークモデルを示しました。 図中の数字はニューロンの数を表します。入力層と出力層のニューロン数 26 とは,もちいた語彙数が 26 であったことを表します。

from [@Elman1991startingsmall]
エルマンは,系列予測課題によって次の単語を予想することを繰り返し学習させた結果,文法構造がネットワークの結合係 数として学習されることを示しました。Elman ネットによって,埋め込み文の処理,時制の一致,性や数の一致,長距離依 存などを正しく予測できることが示されました(Elman, 1990, 1991, 1993)。
- S $\rightarrow$ NP VP “.”
-
NP $\rightarrow$ PropN N N RC - VP $\rightarrow$ V (NP)
-
RC $\rightarrow$ who NP VP who VP (NP) -
N $\rightarrow$ boy girl cat dog boys girls cats dogs -
PropN $\rightarrow$ John Mary - V $\rightarrow$ chase | feed | see | hear | walk | live | chases | feeds | seeds | hears | walks | live s
これらの規則にはさらに 2 つの制約があります。
- N と V の数が一致していなければならない
- 目的語を取る動詞に制限がある。例えばhit, feed は直接目的語が必ず必要であり,see とhear は目的語をとってもとらなくても良い。walk とlive では目的語は不要である。
文章は 23 個の項目から構成され,8 個の名詞と 12 個の動詞,関係代名詞 who,及び文の終端を表すピリオドです。 この文法規則から生成される文 S は,名詞句 NP と動詞句 VP と最後にピリオドから成り立っている。 名詞句 NP は固有名詞 PropN か名詞 N か名詞に関係節 RC が付加したものの何れかとなります。 動詞句 VP は動詞 V と名詞句 NP から構成されるが名詞句が付加されるか否かは動詞の種類によって定まる。 関係節 RC は関係代名詞 who で始まり,名詞句 NP と動詞句 VP か,もしくは動詞句だけのどちらかかが続く,というものです。
下図に訓練後の中間層の状態を主成分分析にかけた結果を示しました。”boy chases boy”, “boy sees boy”, および “boy walks” という文を逐次入力した場合の遷移を示しています。 同じ文型の文章は同じような状態遷移を辿ることが分かります。
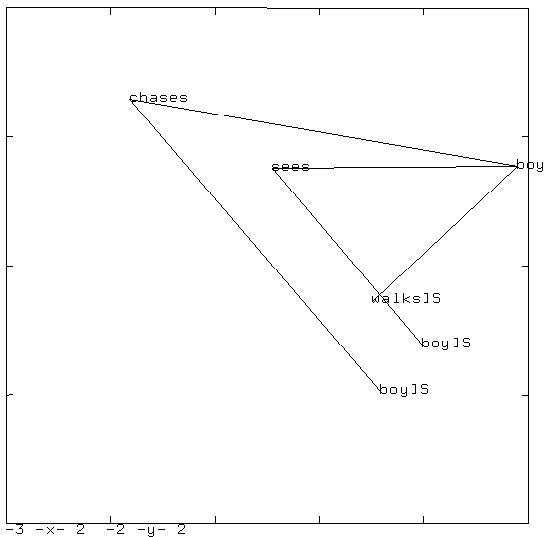
下図は文 “boy chases boy who chases boy” を入力した場合の遷移図です。この文章には単語 “boy” が 3 度出てきます。
それぞれが異なるけれど,他の単語とは異なる位置に附置されていることがわかります。
同様に ‘chases” が 2 度出てきますが,やはり同じような位置で,かつ,別の単語とは異なる位置に附置されています。
世界モデル
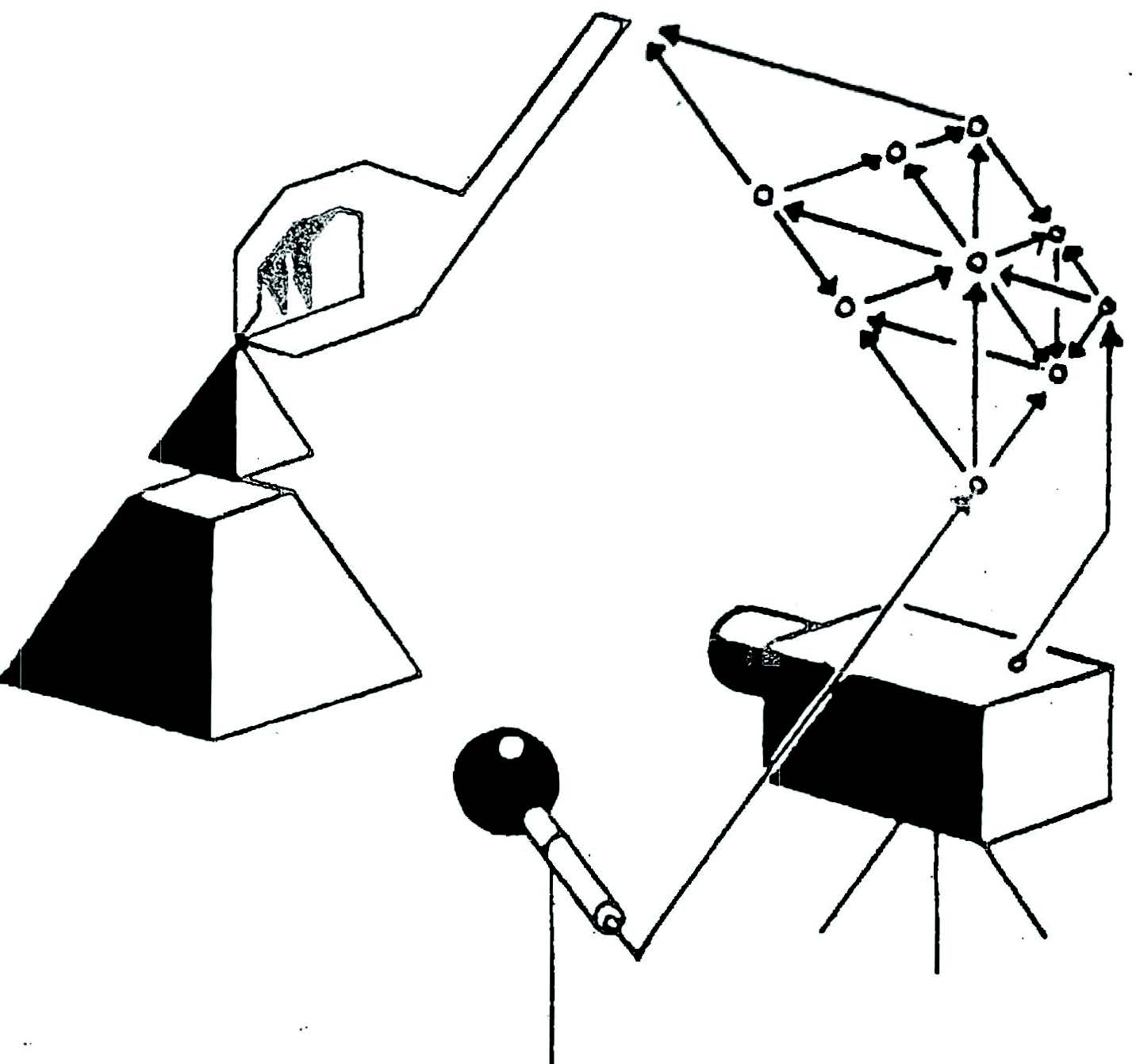


世界モデル カーレース
エージェントモデル
世界モデルでは,エージェントは見たものを小さな代表的なコードに圧縮する視覚的な感覚成分を持っている。 また,過去の情報に基づいて将来のコードの予測を行う記憶成分も持っている。 最後に,我々のエージェントは,視覚と記憶の成分によって作成された表現のみに基づいて,取るべき行動を決定する意思 決定成分を持っている。

我々のエージェントは,密接に連携する 3 つの成分で構成されている: 視覚(V),記憶(M),コントローラ(C) である。
VAE(V)モデル
環境は,各時間ステップでエージェントに高次元の入力観測を与える。 この入力は通常,動画系列の一部である 2D 画像フレームである。 V モデルの役割は,観察された各入力フレームの抽象的で圧縮表現を学習することである。

-
去年までスタンフォード大学の大学院生。現在はステラ自動車,イーロン・マスクが社長,の AI 部長さんです。 ↩